


编译技术课程设计
班 级
学 号
姓 名
指导老师
二零一零年 七 月
一、目的
<<编译技术>>是理论与实践并重的课程,而其实验课要综合运用一、二年级所学的多门课程的内容,用来完成一个小型编译程序。从而巩固和加强对词法分析、语法分析、语义分析、代码生成和报错处理等理论的认识和理解;培养学生对完整系统的独立分析和设计的能力,进一步培养学生的独立编程能力。
二、任务及要求
基本要求:
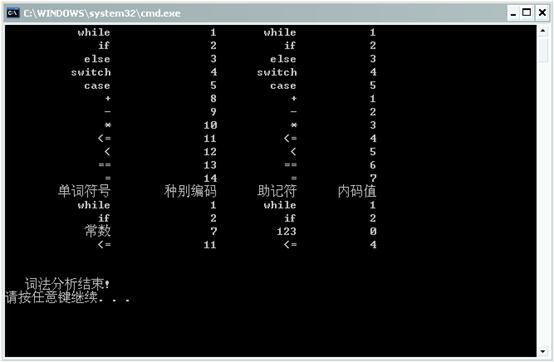
1.词法分析器 产生下述小语言的单词序列
这个小语言的所有的单词符号,以及它们的种别编码和内部值如下表:
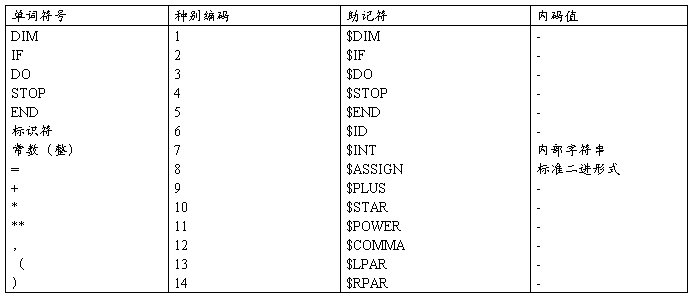
对于这个小语言,有几点重要的限制:
首先,所有的关键字(如IF?WHILE等)都是“保留字”。所谓的保留字的意思是,用户不得使用它们作为自己定义的标示符。例如,下面的写法是绝对禁止的:
IF(5)=x
其次,由于把关键字作为保留字,故可以把关键字作为一类特殊标示符来处理。也就是说,对于关键字不专设对应的转换图。但把它们(及其种别编码)预先安排在一张表格中(此表叫作保留字表)。当转换图识别出一个标识符时,就去查对这张表,确定它是否为一个关键字。
再次,如果关键字、标识符和常数之间没有确定的运算符或界符作间隔,则必须至少用一个空白符作间隔(此时,空白符不再是完全没有意义的了)。例如,一个条件语句应写为
IF i>0 i= 1;
而绝对不要写成
IFi>0 i=1;
因为对于后者,我们的分析器将无条件地将IFI看成一个标识符。
这个小语言的单词符号的状态转换图,如下图:
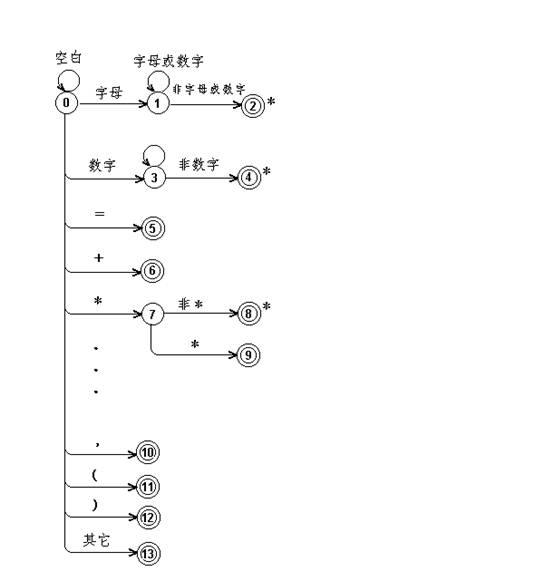
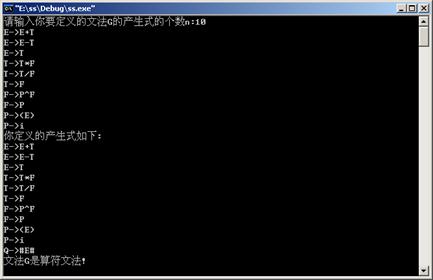
2.语法分析器 能识别由加+ 减- 乘* 除/ 乘方^ 括号()操作数所组成的算术表达式,其文法如下:
E→E+T|E-T|T
T→T*F|T/F|F
F→P^F|P
p→(E)|i
使用的算法可以是:预测分析法;递归下降分析法;算符优先分析法;LR分析法等。
3.中间代码生成器 产生上述算术表达式的中间代码(四元式序列)
三、实现过程说明
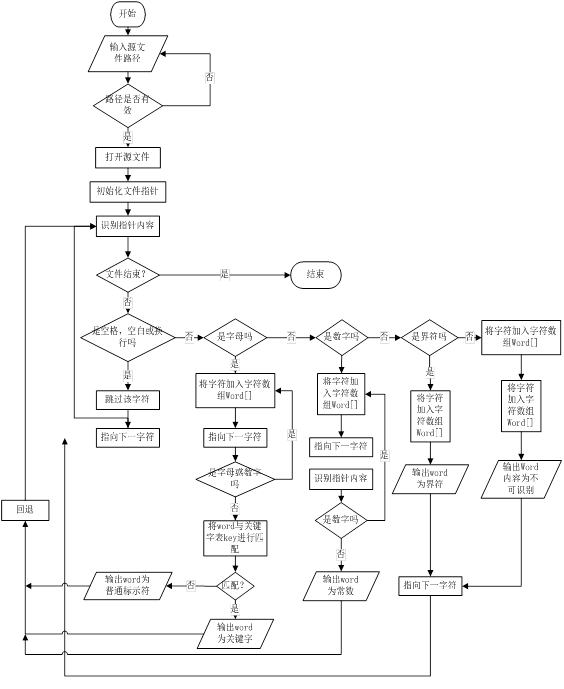
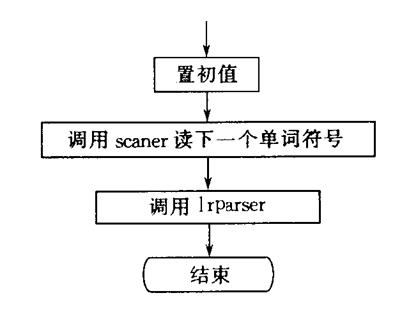
给出各题目的详细算法描述,数据结构和函数说明,流程图。
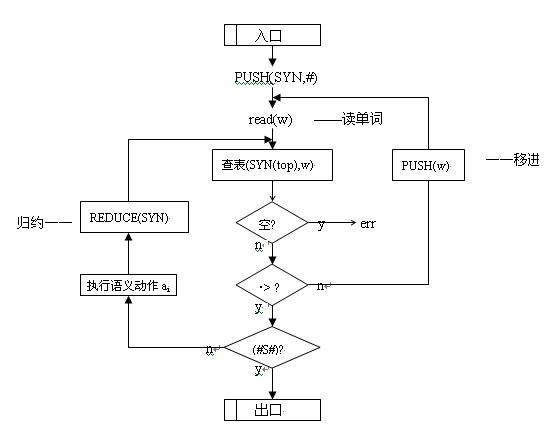
1、词法分析器的流程图
2、语法分析器主程序图
3、中间代码生成器流程图:
四、源程序清单
词法分析器
#include "stdafx.h"
#include "Word.h"
//构造函数,对数据成员初始化,并将关键字以及运算符读入
Word::Word()
{//打开关键字文件
fstream keywordfile("keyword.txt");
if(!keywordfile)
{
cout<<"error ! can't open keywordfile!"<
system("pause");
exit(1);
}
//设置临时变量将关键字、符号文件中的内容存储
string tempword;
int tempencode;
string tempre;
int tempvalue;
//开始读关键字文件
while(!(keywordfile.eof()))
{ keywordfile>>tempword>>tempencode>>tempre>>tempvalue;
keywordlist.push_back(tempword);
keywordencode.push_back(tempencode);
keywordre.push_back(tempre);
keywordcodevalue.push_back(tempvalue);
}
//关闭关键字文件
keywordfile.close();
for(int i=0;i
{cout<
}
fstream signwordfile("signword.txt");
if(!signwordfile)
{ cout<<"error ! can't open signwordfile!"<
system("pause");
exit(1);
}
//开始读符号文件
while(!(signwordfile.eof()))
{
signwordfile>>tempword>>tempencode>>tempre>>tempvalue;
signlist.push_back(tempword);
signencode.push_back(tempencode);
signre.push_back(tempre);
signcodevalue.push_back(tempvalue);
}
//关闭符号文件
signwordfile.close();
for(int i=0;i
{cout<
}
}
//将token中的字符串与character中的字符连接作为token中新的字符串
void Word::concatentation()
{for(int i=0;i<100;i++)
{if(token[i]==NULL)
{token[i]=s;
break;
}
}
}
//判断character中的字符是否为字母和数字的布尔函数,是则返回true,否则返回false
bool Word::letter()
{ if(s<='z' && s>='a' )
return true;
else if(s<='Z' && s>='A')
return true;
else
return false;
}
bool Word::digit()
{ if(s<='9' && s>='0')
return true;
return false;
}
//按token数组中的字符串中的前五项(即判别其是否为保留字),若是保留字则返回它的编码
int Word::reserve()
{
int leng;//记录token数组中单词的长度
for(int i=0;i<100;i++)//计算token数组中单词的长度
{
if(token[i]==NULL)
{
leng=i;
break;
}
}
for(int i=0;i
{
for(int j=0;j
{
if(keywordlist[i][j]!=token[j])//若某个字符不等则终止此次循环
break;
if(j+1==keywordlist[i].length())//若比较字符全部相等,则判断两者是否长度相等
{
if(leng==keywordlist[i].length())
{return i+1;}
else
return 0;
}
}
}
return 0;
}
//将标识符登录到符号表中或将常数登录到常数表中
void Word::buildlist()
{//设置临时变量将标识符的助记符保存
string tempword;
int tempencode;
string tempre;//标识符助记
int tempvalue;
int tempconstre;//常数助记
s=token[0];
if(letter())//第一个字符如果为字母,则将标识符登录到符号表中
{ fstream chartostring("convert.txt");
if(!chartostring)
{
cout<<"Error! Can't open convert file"<
system("pause");
}
for(int i=0;i<100;i++)
{
if(token[i]==NULL)
break;
else
{chartostring<
}
chartostring<
chartostring.close();
chartostring.open("convert.txt");
if(!chartostring)
{
cout<<"Error! Can't open convert file"<
system("pause");
}
chartostring>>tempre;
chartostring.close();
indentityre.push_back(tempre);
tempword="标识符";
tempencode=6;
tempvalue=indentityre.size();
indentitylist.push_back(tempword);
indentityencode.push_back(tempencode);
indentitycodevalue.push_back(tempvalue);
fstream indentityfile("indentityword.txt");
if(!indentityfile)
{ cout<<"Error! Can't open indentityword file"<
system("pause");
}
//先将文件指针移到最后去,再写入一个endl
indentityfile.seekg(0,ios::end);
indentityfile<
indentityfile.seekg(0,ios::end);
indentityfile<
indentityfile.close();
}
else//token中存储的是常数
{
//将token中的字符数字转换为int类型
fstream chartoint("convert.txt");
if(!chartoint)
{
cout<<"Error! Can't open convert file"<
system("pause");
}
for(int i=0;i<100;i++)
{ if(token[i]==NULL)
break;
else
{
chartoint<
}
}
chartoint<
chartoint.close();
chartoint.open("convert.txt");
if(!chartoint)
{ cout<<"Error! Can't open convert file"<
system("pause");
exit(1);
}
chartoint>>tempconstre;
chartoint.close();
constlist.push_back(tempword);
tempword="常数";
tempencode=7;
tempvalue=indentityre.size();
constencode.push_back(tempencode);
constre.push_back(tempconstre);
constvalue.push_back(tempvalue);
fstream constdigit("constdigit.txt");
if(!constdigit)
{
cout<<"Error! Can't open constdigit file!"<
system("pause");
exit(1);
}
//先将文件指针移到最后去,再写入一个endl
constdigit.seekg(0,ios::end);
constdigit<
constdigit.seekg(0,ios::end);
constdigit<
constdigit.close();
cout<
}
}
//出现非法字符,显示错误信息
void Word::error()
{
cout<<"Error! Error word!"<
system("pause");
}
void Word::signinfor()
{
//按token数组中的字符串中的前五项(即判别其是否为保留字),若是保留字则返回它的编码
int leng;//记录token数组中单词的长度
for(int i=0;i<100;i++)//计算token数组中单词的长度
{
if(token[i]==NULL)
{
leng=i;
break;
}
}
for(int i=0;i
{
for(int j=0;j
{
if(signlist[i][j]!=token[j])//若某个字符不等则终止此次循环
break;
if(j+1==signlist[i].length())//若比较字符全部相等,则判断两者是否长度相等
{
if(leng==signlist[i].length())
{
cout<
}
}
}
}
}
//词法分析的函数
void Word::run()
{
cout<
fstream file("word.txt");
if(!file)
{
cout<<"error,can't open file"<
system("pause");
exit(1);
}
file.unsetf(ios::skipws);
while(s!='#' && !file.eof())
{
for(int i=0;i<100;i++)
{
token[i]=NULL;
}
file>>s;
while(s==' ')
{
file>>s;
}
switch(s)
{
case 'a';
case 'b':
case 'c':
case 'd':
case 'e':
case 'f':
case 'g':
case 'h':
case 'i':
case 'j':
case 'k':
case 'l':
case 'm':
case 'n':
case 'o':
case 'p':
case 'q':
case 'r':
case 's':
case 't':
case 'u':
case 'v':
case 'w':
case 'x':
case 'y':
case 'z':
while(letter()||digit())
{
concatentation();//将当前读入的字符送入token数组
file>>s;//继续读字符,直到字符不为数字或字母为止
}
//扫描指针回退一个字符
file.seekg(-1,ios::cur);
code=reserve();
if(!code)
{ buildlist();}
else
{
cout<
}
break;
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
while(digit())
{
concatentation();//将当前读入的字符送入token数组
file>>s;//继续读字符,直到字符不为数字为止
}
//扫描指针回退一个字符
file.seekg(-1,ios::cur);
buildlist();
break;
case '+':
concatentation();
signinfor();
break;
case '-':
concatentation();
signinfor();
break;
case '*':
concatentation();
signinfor();
break;
case '<':
concatentation();
file>>s;
if(s!='=')
{//扫描指针回退一个字符
file.seekg(-1,ios::cur);
signinfor();
}
else
{
concatentation();
signinfor();
}
break;
case '=':
concatentation();
file>>s;
if(s!='=')
{
//扫描指针回退一个字符
file.seekg(-1,ios::cur);
signinfor();
}
else
{
concatentation();
signinfor();
}
break;
case ';':
concatentation();
signinfor();
break;
case '#':
cout<
cout<
cout<
system("pause");
exit(1);
default:
error();
}
}
file.close();
}
void main()
{
Word word;
word.run();
system("pause");
}
运行结果:
语法分析器 源程序:
#include
#include
#include
typedef struct
{
char R;
char r;
int flag;
}array;
typedef struct
{
char E;
char e;
}charLode;
typedef struct
{
charLode *base;
int top;
}charstack;
char str[80][80],arr[80][80],brr[80][80];
array F[20];
int m,kk,p,ppp,FF=1;
char r[10];
int crr[20][20],FLAG=0;
char ccrr1[1][20],ccrr2[20][1];
void Initstack(charstack &s)//定义栈
{
s.base=new charLode[20];
s.top=-1;
}
void push(charstack &s,charLode w)
{
s.top++;
s.base[s.top].E=w.E;
s.base[s.top].e=w.e;
}
void pop(charstack &s,charLode &w)
{
w.E=s.base[s.top].E;
w.e=s.base[s.top].e;
s.top--;
}
int IsEmpty(charstack s)
{
if(s.top==-1)
return 1;
else return 0;
}
int IsLetter(char ch)
{
if(ch>='A'&&ch<='Z')
return 1;
else return 0;
}
//judge1是判断是否是算符文法:若产生式中含有两个相继的非终结符则不是算符文法
int judge1(int n)
{
int j=3,flag=0;
for(int i=0;i<=n;i++)
while(str[i][j]!='\0')
{
char a=str[i][j];
char b=str[i][j+1];
if(IsLetter(a)&&IsLetter(b))
{flag=1;break;}
else j++;
}
if(flag==1)
return 0;
else
return 1;
}
//judge2是判断文法G是否为算符优先文法:若不是算符文法或若文法中含空字或终结符的优先级不唯一则不是算符优先文法
void judge2(int n)
{
for(int i=0;i<=n;i++)
if(str[i][3]=='~'||judge1(n)==0||FLAG==1)//'~'代表空字
{cout<<"文法G不是算符优先文法!"<
cout<<"文法G是算符优先文法!"<
//search1是查看存放终结符的数组r中是否含有重复的终结符
int search1(char r[],int kk,char a)
{
for(int i=0;i
break;
if(i==kk) return 0;
else return 1;
}
//createF函数是用F数组存放每个终结符与非终结符和组合,并且值每队的标志位为0;F数组是一个结构体
void createF(int n)
{
int k=0,i=1;char g;
char t[10];//t数组用来存放非终结符
t[0]=str[0][0];
while(i<=n)
{
if(t[k]!=str[i][0])
{k++;t[k]=str[i][0];g=t[k];i++;}
else i++;
}
kk=0;
char c;
for(i=0;i<=n;i++)
{ int j=3;
while(str[i][j]!='\0')
{
c=str[i][j];
if(IsLetter(c)==0)
{
if(!search1(r,kk,c))
r[kk]=c;kk++;//r数组用来存放终结符
}
j++;
}
}
m=0;
for(i=0;i
F[m].R=t[i];
F[m].r=r[j];
F[m].flag=0;
m++;
}
}
//search函数是将在F数组中寻找到的终结符与非终结符对的标志位值为1
void search(charLode w)
{
for(int i=0;i
{F[i].flag=1;break;}
}
void FirstVT(int n)//求FirstVT
{
charstack sta;
charLode w;
int i=0;
Initstack(sta);
while(i<=n)
{
int k=3;
w.E=str[i][0];
char a=str[i][k];
char b=str[i][k+1];
if(!IsLetter(a))//产生式的后选式的第一个字符就是终结符的情况
{
w.e=a;
push(sta,w);
search(w);
i++;
}
else if(IsLetter(a)&&b!='\0'&&!IsLetter(b))//产生式的后选式的第一个字符是非终结符的情况
{
w.e=b;
push(sta,w);
search(w);
i++;
}
else i++;
}
charLode ww;
while(!IsEmpty(sta))
{
pop(sta,ww);
for(i=0;i<=n;i++)
{
w.E=str[i][0];
if(str[i][3]==ww.E&&str[i][4]=='\0')
{
w.e=ww.e;
push(sta,w);
search(w);
break;
}
}
}
p=0;int k=1;i=1;
while(i
if(F[i-1].flag==1)
{
arr[p][0]=F[i-1].R;
arr[p][k]=F[i-1].r;
}
while(F[i].flag==0&&i
if(F[i].flag==1)
{
if(F[i].R==arr[p][0])
k++;
else {arr[p][k+1]='\0';p++;k=1;}
i++;
}
}
}
void LastVT(int n)//求LastVT
{
charstack sta;
charLode w;
for(int i=0;i
i=0;
Initstack(sta);
while(i<=n)
{
int k=strlen(str[i]);
w.E=str[i][0];
char a=str[i][k-1];
char b=str[i][k-2];
if(!IsLetter(a))
{
w.e=a;
push(sta,w);
search(w);
i++;
}
else if(IsLetter(a)&&!IsLetter(b))
{
w.e=b;
push(sta,w);
search(w);
i++;
}
else i++;
}
charLode ee;
while(!IsEmpty(sta))
{
pop(sta,ee);
for(i=0;i<=n;i++)
{
w.E=str[i][0];
if(str[i][3]==ee.E&&str[i][4]=='\0')
{
w.e=ee.e;
push(sta,w);
search(w);
}
}
}
int k=1;i=1;
ppp=0;
while(i
if(F[i-1].flag==1)
{
brr[ppp][0]=F[i-1].R;
brr[ppp][k]=F[i-1].r;
}
while(F[i].flag==0&&i
if(F[i].flag==1)
{
if(F[i].R==arr[ppp][0])
k++;
else {brr[ppp][k+1]='\0';ppp++;k=1;}
i++;
}
}
}
void createYXB(int n)//
{
int i,j;
for(j=1;j<=kk;j++)
ccrr1[0][j]=r[j-1];
for( i=1;i<=kk;i++)
ccrr2[i][0]=r[i-1];
for(i=1;i<=kk;i++)
for(j=1;j<=kk;j++)
crr[i][j]=0;
int I=0,J=3;
while(I<=n)
{
if(str[I][J+1]=='\0')
{I++;J=3;}
else
{
while(str[I][J+1]!='\0')
{
char aa=str[I][J];
char bb=str[I][J+1];
if(!IsLetter(aa)&&!IsLetter(bb))//优先及等于的情况,用1值表示等于
{
for(i=1;i<=kk;i++)
{
if(ccrr2[i][0]==aa)
break;
}
for(j=1;j<=kk;j++)
{
if(ccrr1[0][j]==bb)
break;
}
if(crr[i][j]==0)
crr[i][j]=1;
else {FLAG=1;I=n+1;}
J++;
}
if(!IsLetter(aa)&&IsLetter(bb)&&str[I][J+2]!='\0'&&!IsLetter(str[I][J+2]))//优先及等于的情况
{
for(i=1;i<=kk;i++)
{
if(ccrr2[i][0]==aa)
break;
}
for(int j=1;j<=kk;j++)
{
if(ccrr1[0][j]==str[I][J+2])
break;
}
if(crr[i][j]==0)
crr[i][j]=1;
else {FLAG=1;I=n+1;}
}
if(!IsLetter(aa)&&IsLetter(bb))//优先及小于的情况,用2值表示小于
{
for(i=1;i<=kk;i++)
{
if(aa==ccrr2[i][0])
break;
}
for(j=0;j<=p;j++)
{
if(bb==arr[j][0])
break;
}
for(int mm=1;arr[j][mm]!='\0';mm++)
{
for(int pp=1;pp<=kk;pp++)
{
if(ccrr1[0][pp]==arr[j][mm])
break;
}
if(crr[i][pp]==0)
crr[i][pp]=2;
else {FLAG=1;I=n+1;}
}
J++;
}
if(IsLetter(aa)&&!IsLetter(bb))//优先及大于的情况,用3值表示大于
{
for(i=1;i<=kk;i++)
{
if(ccrr1[0][i]==bb)
break;
}
for(j=0;j<=ppp;j++)
{
if(aa==brr[j][0])
break;
}
for(int mm=1;brr[j][mm]!='\0';mm++)
{
for(int pp=1;pp<=kk;pp++)
{
if(ccrr2[pp][0]==brr[j][mm])
break;
}
if(crr[pp][i]==0)
crr[pp][i]=3;
else {FLAG=1;I=n+1;}
}
J++;
}
}
}
}
}
//judge3是用来返回在归约过程中两个非终结符相比较的值
int judge3(char s,char a)
{
int i=1,j=1;
while(ccrr2[i][0]!=s)
i++;
while(ccrr1[0][j]!=a)
j++;
if(crr[i][j]==3) return 3;
else if(crr[i][j]==2)
return 2;
else if(crr[i][j]==1)
return 1;
else return 0;
}
void print(char s[],char STR[][20],int q,int u,int ii,int k)//打印归约的过程
{
cout<
cout<
for(i=q;i<=ii;i++)
cout<
}
void process(char STR[][20],int ii)//
{
cout<<"步骤"<<" "<<"符号栈"<<" "<<"输入串"<<" "<<"动作"<
char s[40],a;
s[k]='#';
print(s,STR,q,u,ii,k);
cout<<"
s[k]=STR[0][q];
q++;
print(s,STR,q,u,ii,k);
cout<<"
{
a=STR[0][q];
if(!IsLetter(s[k])) j=k;
else j=k-1;
b=judge3(s[j],a);
if(b==3)//
{
while(IsLetter(s[j-1]))
j--;
for(i=j;i<=k;i++)
s[i]='\0';
k=j;s[k]='N';u++;
print(s,STR,q,u,ii,k);
cout<<"归约"<
else if(b==2||b==1)//
{
k++;
s[k]=a;
u++;
q++;
print(s,STR,q,u,ii,k);
if(s[0]=='#'&&s[1]=='N'&&s[2]=='#')
cout<<"接受"<
else
{cout<<"
if(s[0]=='#'&&s[1]=='N'&&s[2]=='#')
cout<<"
void main()
{
int n,i,j;
cout<<"
cin>>n;
for(i=0;i
gets(str[i]);
j=strlen(str[i]);
str[i][j]='\0';
}
str[i][0]='Q';
str[i][1]='-';
str[i][2]='>';
str[i][3]='#';
str[i][4]=str[0][0];
str[i][5]='#';
str[i][6]='\0';
cout<<"
cout<
cout<<"文法G不是算符文法!"<
{
cout<<"
FirstVT(n);
LastVT(n);
createYXB(n);
}
judge2(n);//
if(FLAG==0)
{
for(i=0;i<=p;i++)//打印FirstVT
{
cout<<"FirstVT("<
cout<
cout<<"FirstVT(Q)={#}"<
{
cout<<"LastVT("<
cout<
cout<<"LastVT(Q)={#}"<
{
cout<<" ";
cout<
cout<
cout<
if(crr[i][j]==0)
cout<<" ";
else if(crr[i][j]==1)
cout<<"=";
else if(crr[i][j]==2)
cout<<"<";
else if(crr[i][j]==3)
cout<<">";
cout<<" ";
}
cout<
}
if(FF==1)
{
char STR[1][20];
cout<<"
int ii=strlen(STR[0]);
STR[0][ii]='#';
cout<<"
}
}
运算结果:
中间代码生成器源程序:
/*
表达式生成四元式
递归子程序法
*/
#include
#include
#include
#include
#include
#define STACK_INIT_SIZE 50
#define STACKINCREMENT 5
#define ERROR 0
#define OVERFLOW -2
#define TRUE 1
#define FALSE 0
#define OK 1
#define NULL 0
void sub_E();
void sub_F();
void sub_T();
void sub_G();
void GEQ(char m);
void PRINT();
typedef struct Stack
{
char *base;
char *top;
int stacksize;
}Stack;
int num=0;
char QT[10][4],T='A',c;
struct Stack SEM;
struct initStack(Stack s)
{
s.base=(char *)malloc(STACK_INIT_SIZE*sizeof(char));
if(!s.base)
exit(OVERFLOW);
s.top=s.base;
s.stacksize=STACK_INIT_SIZE;
return OK;
}
//初始化堆栈
char pop(Stack &s)
{
char e;
if(s.top==s.base)
{printf("栈中已无元素!");
exit(ERROR);
}
e=*--s.top;
return e;
}
//出栈
struct push(Stack &s,char e)
{
if(s.top-s.base>=s.stacksize)
{
s.base=(char *)realloc(s.base,(s.stacksize+STACKINCREMENT)*sizeof(char));
if(!s.base)
exit(OVERFLOW);
s.top=s.base+s.stacksize;
s.stacksize+=STACKINCREMENT;
}
*s.top++=e;
return OK;
}
//入栈
void main()
{
initStack(SEM);
printf("----表达式应由小写字母、运算符及小括号组成,并以\"#\"结束----\n");
printf("请输入表达式:");
c=getchar();
sub_E();
if(c=='#')
PRINT();
else
{
printf("无结束符或漏写运算符!");
exit(0);
}
getchar();
}
void sub_E()
{
sub_T();
R1: if(c=='+')
{
c=getchar();
sub_T();
GEQ('+');
goto R1;
}
else if(c=='-')
{
c=getchar();
sub_T();
GEQ('-');
goto R1;
}
else ;
}
void sub_T()
{
sub_G();
R4: if(c=='*')
{ c=getchar();
sub_F();
GEQ('*');
goto R4;
}
else if(c=='/')
{
c=getchar();
sub_F();
GEQ('/');
goto R4;
}
}
void sub_F()
{
sub_G();
R5: if(c=='^')
{
c=getchar();
sub_G();
GEQ('^');
goto R5;
}
}
void sub_G()
{
if(c>='a'&&c<='z')
{
push(SEM,c);
c=getchar();
}
else if(c=='(')
{
c=getchar();
sub_E();
if(c==')')
c=getchar();
else
{
printf("括号不匹配!");
exit(0);
}
}
else
{
printf("非法符号!");
exit(0);
}
}
void GEQ(char m)
{
QT[num][0]=m;
QT[num][2]=pop(SEM);
QT[num][1]=pop(SEM);
QT[num][3]=T;
push(SEM,T);
num++;
T++;
}
void PRINT()
{
printf("您输入的表达式所对应的四元式为:\n");
for(int i=0;i
{
printf("(");
printf("%c",QT[i][0]);
if(QT[i][1]<='Z'&&QT[i][1]>='A')
printf("\t%c%d",'t',QT[i][1]-'A'+1);
else
printf("\t%c",QT[i][1]);
if(QT[i][2]<='Z'&&QT[i][1]>='A')
printf("\t%c%d",'t',QT[i][2]-'A'+1);
else
printf("\t%c",QT[i][2]);
if(QT[i][3]<='Z'&&QT[i][1]>='A')
printf("\t%c%d",'t',QT[i][3]-'A'+1);
else
printf("\t%c",QT[i][3]);
printf(")\n");
}
}
六、总结
谈谈自己的收获与体会。
1、 通过这次实验,我对词法分析器有了进一步的了解,把理论知识应用于实验中。也让我重新熟悉了C语言的相关内容,加深了对C语言知识的深化和用途的理解。通过这次语义分析的实验, 我对高级语言的学习有了更深的认识 ,了解得更透彻。
2、 我了解了高级语言转化为目标代码或汇编指令的过程,。对今后的学习将起很大的作用,对以后的编程有很大的帮助. 本次实验虽然只是完成了一个简单的程序,并且程序的主要框架课本上有给出,但在组织程序结构和深入了确上学到了很多,加深对编译原理的理解,掌握编译程序的实现方法和技术。巩固了前面所学的知识。